
index 는 데이터베이스 테이블의 검색 속도를 향상시키기 위한 방법 중 하나이다.
많은 예시에서 책갈피로 불리는 index에 대해서 자세히 알아보자.

사진에서 볼 수 있듯이, 테이블에 Full Scan 으로 값을 찾기 전 빠르게 해당 데이터의 위치를 찾아 효율을 높이기 위해서 index를 사용한다.
다만 SELECT 를 제외하고, UPDATE, DELETE, INSERT 명렁어를 사용하는 sql일 경우 오히려 성능이 저하될 수 있다.
해당 데이터가 변경되면 인덱스에도 적용해야하기 때문에 추가적인 작업이 필요하기 때문이다.
결론은 해당 서비스 로직과 데이터베이스 테이블의 특징을 면밀히 분석해 index 를 적용했을 때 성능이 향상될 거 같다고 판단될 때 사용해야한다. 인턴을 경험해보니, 대규모 데이터의 SELECT 의 명령이 자주 일어나는 테이블에 대해서는 대부분 index와 Cache 가 적용되는 거 같았다.
[ index 를 사용하면 좋은 상황]
- 대용량의 데이터가 들어가있는 테이블을 다룰 때 (하나의 쿼리가 요청될 때마다, Full Scan 하게 되면 ,,,, 상상도 하기 싫다)
- 데이터가 자주 바뀌지 않는 상황.
- JOIN, WHERE, ORDER 등 자주 사용되는 테이블일 경우 인덱스를 잘 설정해야한다.
그럼 index 는 어떻게 구현할까 ?
크게 2가지 방법으로 구현한다. Hash Map 과 B+Tree 이다.
Hash Map
index에서 사용하기 힘든 자료구조 이기 때문에 간단하게 설명하겠다. 기본적으로 key-value 구조를 가지며 key 값에 검색할 데이터 컬럼을 넣은 후, value 값에 테이블에 저장되어 있는 위치를 저장한다. 때문에 해시 테이블의 시간복잡도는 O(1) 이 되며, 매우 빠르다. 하지만 함정이 있다. 바로 (=) 연산에만 작용된다는 점이다.
해시 값은 값이 조금이라도 변하면 완전 다른 값이 된다. 때문에 값 끼리의 비교를 할 수 없는 것이다. index특성상 부등호 혹은 %, _ 과 같은 문자열 연산이 들어가는 경우가 많은데 이에 적용할 수 없으니 사용하지 않는 것이다.
B+ Tree
Tree 구조를 가지며 하나의 노드가 여러개의 데이터를 가질 수 있는 B-Tree 를 index에 사용하기 적합하게 확장한 새로운 자료구조이다. B-Tree 의 특징을 간단히 살펴보자
- 항상 정렬된 상태를 유지
- 하나의 노드가 여러개의 데이터를 가질 수 있음 (데이터에 접근할 때 빠름)
- 노드 내 데이터의 개수가 n개일 때, 자식 데이터의 개수는 n+1개
- 균일하기 때문에, 리프노드에 접근하는 시간은 모두 동일하다.
B+Tree는 B-Tree의 확장한 개념이기 때문에 같은 특징이 있지만, 큰 차이점이 있다.
B-Tree가 leaf-node 외에도 key-value 모두 담을 수 있다는 점에 비해, B+Tree 는 leaf-node를 제외하면 key 값만 담아둘 수 있다. 즉 leaf-node 들만 key-value 값이 들어가기 때문에 메모리 적으로 이득을 볼 수 있는 것이다.
이러한 이득은 value를 넣는 공간에 더 많은 key를 담을 수 있고, 이는 속도 증가의 결과를 낳게된다.
또한 index Full Scan 시 leaf 노드들만 선형탐색 하면 되기 때문에 또 장점이 있다고 한다.
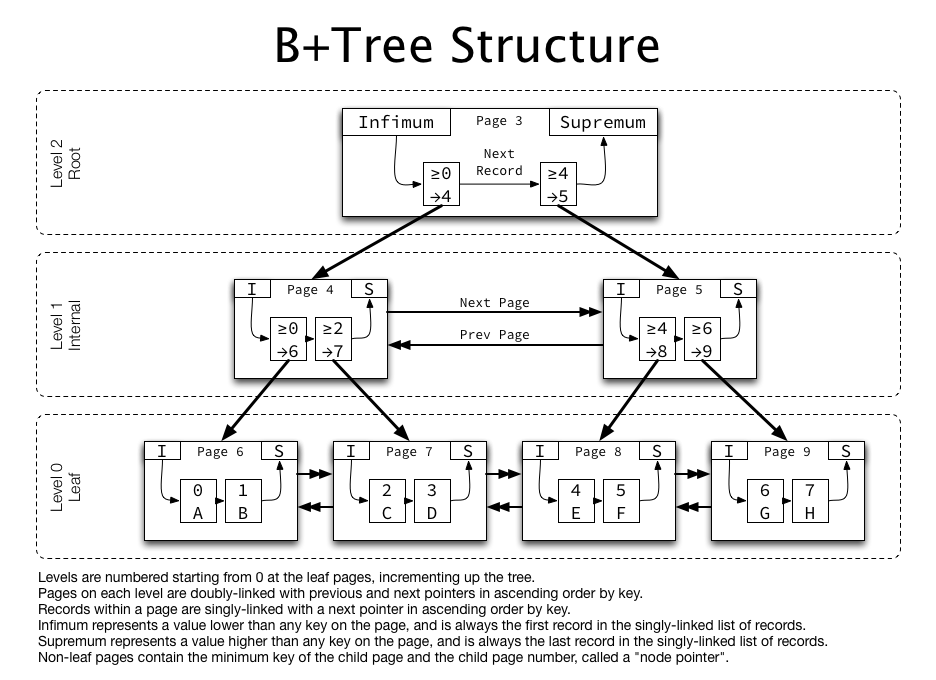
이렇게 leaf node 들을 제외하면 모두 key 값만 들고 있으며 leaf-node 끼리는 Linked-List 로 연결되어 있다.
'개인 공부 > 전공 지식 정리' 카테고리의 다른 글
| [Network] WEB vs WAS (0) | 2022.07.06 |
|---|---|
| [Socket] WebSocket 이란 ? (0) | 2022.07.05 |
| [Socket] Http 통신과 Socket 통신의 차이점 (0) | 2022.07.04 |
| [Git] Git - 기초 키워드 정리 (0) | 2022.01.30 |